How to Calculate Statistical Significance

Quick Navigation:
Part II: How to Determine if My Research is Statistically Significant
Refresher: What is Statistical Significance?
What does it mean for research findings to be “statistically significant? ”
Simply stated, statistical significance is a way for researchers to quantify how likely it is that their results are due to chance. Statistically significant findings are those in which the researcher has confidence the results are real and reliable because the odds of obtaining the results just by chance are low.
Statistical significance testing involves several abstract concepts. So, we try to make things concrete with an example of how you might conduct a test of statistical significance.
How to Calculate Statistical Significance
Statistical Significance Testing in Psychological Research
Everyone knows what it’s like to feel regret. But only a few people are interested enough in the feeling of regret to design experiments investigating the behaviors other people might engage in to avoid the feeling. Jane Risen and Thomas Gilovich are two such people.
In a 2008 paper titled, “Why People are Reluctant to Tempt Fate” Risen and Gilovich investigated how people’s fear of feeling regret might lead them to engage in otherwise irrational behavior.
In their first experiment, people read about Jon—a young man who has just applied to graduate school. Jon really wants to attend Stanford, and knowing this, Jon’s mother mails him a Stanford t-shirt. In the scenario, people read that Jon either: a) stuffed the shirt in a drawer, or b) tempted fate by wearing the shirt before hearing from Stanford.
After reading the scenario, people in the study were asked: how likely is Jon to receive acceptance to Stanford (0 – not at all likely to 10 – extremely likely)?
As the authors expected, people who read that Jon wore the t-shirt were less likely to believe he would be accepted to Stanford (M = 5.19, SD = 1.35) than those who read that he stuffed the shirt in a drawer (M = 6.13, SD = 1.02). The question, however, is whether the difference between groups is large enough to be statistically significant.
To find out, the authors engaged in null hypothesis significance testing.
A 5 Step Model for Null Hypothesis Significance Testing
1. State the null and alternative hypotheses
The first step in statistical significance testing is to adopt a null hypothesis. The null hypothesis takes a skeptical stance toward the researchers’ data and assumes that whatever the researcher is studying does not really exist.
In the case of Risen and Gilovich’s experiment, the null hypothesis was that tempting fate—wearing the t-shirt before hearing from Stanford—would have no effect on people’s beliefs about whether Jon will be accepted to Stanford.
The alternative hypothesis, on the other hand, states that there is an effect of tempting fate on people’s beliefs that Jon will be accepted to Stanford.
Two other points about the null and alternative hypotheses are worth mentioning.
First, both hypotheses are often more useful in theory than in practice. Researchers rarely write down their null and alternative hypotheses. Instead, the hypotheses are implicit or assumed as part of statistical analysis.
Second, the null and alternative hypotheses apply to the population the researcher is studying, not the sample. Even though researchers rely on the samples they collect for data, the hypotheses they test and the models underlying them are assumed to occur at the population level (i.e., to people outside of the sample).
2. Set a threshold for statistical significance
The second step in conducting a significance test is to set a threshold for significance. Traditionally, the gold standard within academic research has been a significance level (or p value) of .05. This means researchers are only willing to accept their results as statistically significant if there is less than a 5% chance they would obtain the same results if the null hypothesis were true (i.e., if there is really no effect).
Even though the .05 significance level is common within academia, there is nothing inherently valuable about it. Indeed, more than 30 years ago, two well-respected statisticians highlighted just how arbitrary the .05 significance level is by writing, “…surely, God loves the .06 nearly as much as the .05.” In recent years, some academic researchers have called for the .05 significance level to become more stringent, dropping to .005.
Setting a threshold for statistical significance should occur within the context of your study’s goals. If you are conducting a study for business, the significance level you adopt should be informed by how you plan to use the data. How important is the decision you’re trying to make? What are the consequences of getting the decision wrong? How valuable is the course of action you plan to take if you are right? The answers to these questions might lead you to adopt a very conservative significance level or a more liberal one, perhaps even topping .10 or .20.
Your significance level should balance the desire to be confident in your results with the practical effect of the decision you plan to make.
3. Source a sample and gather data
The third step is gathering data.
Because it is often impractical to gather data from everyone in the population of interest, researchers gather a sample. Data from the sample is used to make inferences about the population.
In Risen and Gilovich’s study, for example, they were interested in the general feeling of regret. Their population of interest could reasonably be described as adults within the US or people from Western, industrialized nations. The sample they gathered, however, consisted of 62 undergraduate students at Cornell.
For many researchers today, the most efficient way to gather data is online. CloudResearch can help you quickly and easily gather data from large and diverse groups of people. Learn how our sampling tools can help you find the sample you need and ensure you have enough power for your statistical tests today.
4. Determine if your data are statistically significant
After gathering data, the next step is to run the statistical tests. There are many different tests researchers can conduct, depending on the type of data they have. In the case of our example, Risen and Gilovich conducted a simple two groups t-test. Other common analyses include linear regression, chi-square tests, ANOVA, and Mann-Whitney u tests.
All statistical tests follow a formula. The t-test formula below converts the difference between two groups into a ratio:
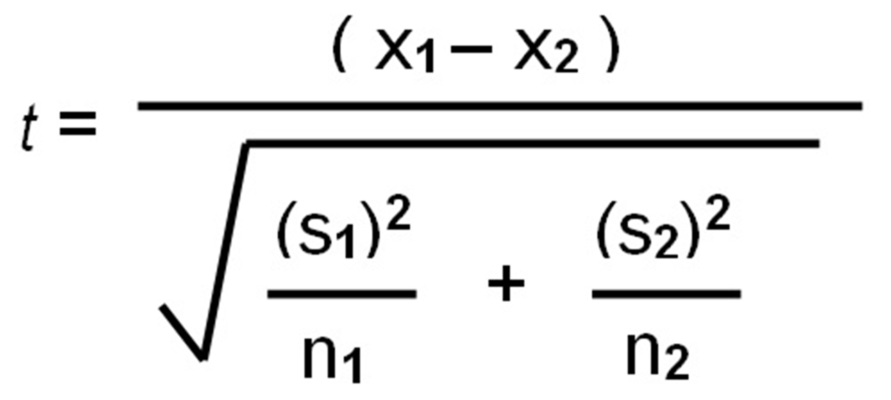
Once researchers have the ratio, they compare it to a probability distribution like the one below. If the t statistic falls beyond the threshold of significance, the researchers reject the null hypothesis and conclude that their effect is statistically significant.
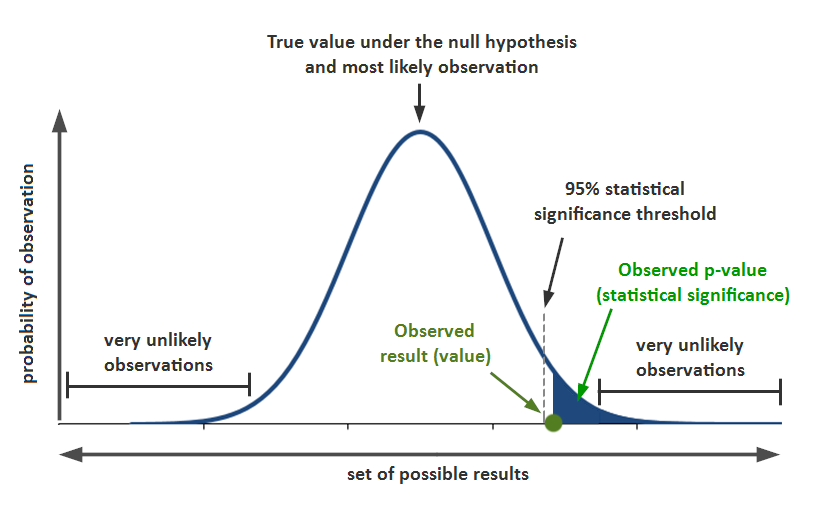
In Risen and Gilovich’s study, for example, the researchers rejected the null hypothesis and concluded that the difference between the two groups was statistically significant because the probability of obtaining a t value equal to 3.01 or greater was 1% (t(60) = 3.01, p = .01, d = 0.78).
Although statistical tests can often be computed by hand, most researchers use an analysis program. Software packages like Tableau, SPSS, and Stata are commercially available and make such computations simple. Yet even in the absence of such software, researchers can often use programs like Microsoft Excel to simplify the execution of statistical analyses.
5. Interpret the results
Once the analyses are complete and you have a statistically significant finding, then what? How should you interpret the data?
Perhaps the first step in interpretation is remembering that your results do not “prove” anything, they simply offer support for your ideas. After all, even if the relationship you are studying does not exist (the null hypothesis is true), you would obtain results below the significance level of .05 five times out of a hundred if you ran the same study over and over.
The second step in interpreting your data is moving beyond the p value and evaluating the finding’s practical significance. In some studies, the practical significance will be apparent because the findings can be interpreted as differences in dollars spent, visits to your webpage, or new contacts created. In other studies, however, the practical significance is more difficult to ascertain.
In the Risen and Gilovich study, for example, it is not immediately clear what the practical significance of the finding is. The study implies that people believe negative consequences may befall someone who tempts fate, but it doesn’t say too much else. In situations like this, researchers often turn to an effect size estimate to understand how strong their findings are. Effect sizes are a quantitative measure of the strength or magnitude of a finding. The effect size in the Risen and Gilovich study was a d of 0.78, which is quite large.
In order to make sound decisions, it’s important for research to be statistically significant. CloudResearch can help with your research by providing quick access to tens of millions of participants. Using our platform, you can be sure you find enough participants to conduct well-powered studies. And, if you don’t have the resources or are unsure how to plan or analyze your study, we’re here to help. We have expert social scientists who can help plan and manage any study you want to run. After the data are gathered, we can conduct advanced statistical analyses and interpret the data for you, saving your team time and resources.




